直播终端优化总结
@(工作)[视频, ijkplayer, 编码]
由来
从接手做第一个版本到现在我们为加快首屏加载速度做过两次优化,到当前本基本上完成了视频秒开的目标。其实当知道加载速度慢的原因后最终的修改其实没什么复杂的,复杂的是分析原因的过程,这里主要分享一下从一开始的外部表现,逐步分析原因,到最终得到优化方案,验证优化成果的流程。希望这个过程也能给其他项目提供一些借鉴。
优化方法
- 明确优化目标
- 1s内实现用户点击房间到首帧渲染完成
- 自顶向下分析:
- 操作流程分解,找到流程中的问题;
- 逐步向底层深入,分析性能瓶颈;
- 得出优化方案
- 数据验证结果
相关概念
在介绍之前为了更好的理解后面的内容,先普及一下直播流程和视频流相关的术语。
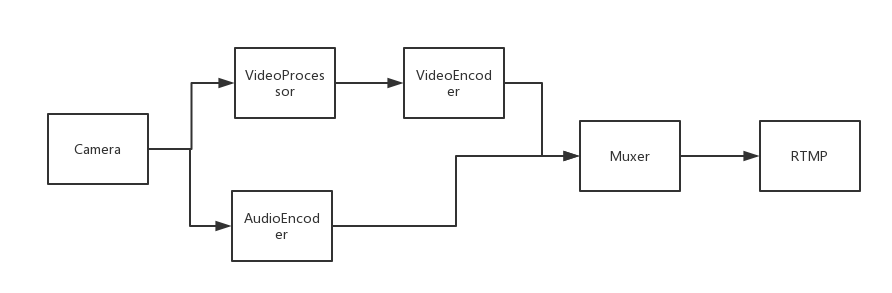
推流流程:
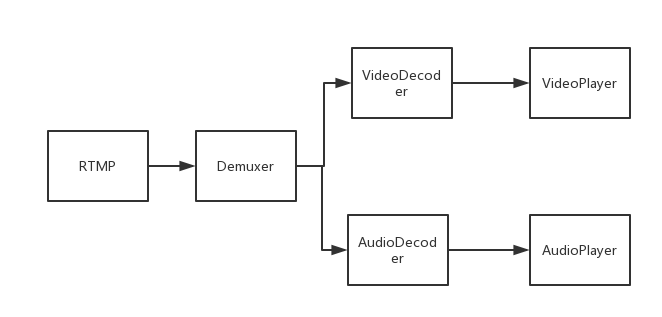
拉流流程:
如图所示,从摄像头和麦克风获取到视频和音频数据,对于视频我们可能还需要做一些处理,比如加美颜滤镜或者其他的处理,这些原始数据是不适合直接在网络上实时传输的,第一是因为原始数据体积比较大,传输效率低;其次是因为要在网络上实时传输音视频,需要将音视频流分解成小块数据包,而原始数据需要添加音视频同步信息保证接收端能还原出完整的音视频流。所以获取到视频流和音频流之后分别进行编码,现在视频编码使用比较高效的H.264,而音频则使用AAC编码格式。 经过编码后,压缩了传输输数据,下一步是视频封装,将压缩后的音视频以某种格式封装,再使用RTMP网络协议封包推送到服务器。
拉流流程是推流的逆过程,只是少了视频处理的步骤。
推拉流流程的各个阶段涉及到一些概念:
FPS:视频每秒包含多少帧,一帧就是一个静态的图像;
I帧,B帧和P帧:I帧是靠尽可能去除图像空间冗余信息来压缩传输数据量的帧内编码图像; P帧是通过充分降低与图像序列中前面已编码帧的时间冗余信息来压缩传输数据量的编码图像,也叫预测帧; B帧是既考虑与源图像序列前面已编码帧,也顾及源图像序列后面已编码帧之间的时间冗余信息来压缩传输数据量的编码图像,也叫双向预测帧;一般地,I帧压缩效率最低,P帧较高,B帧最高。I帧是通过帧内预测编码的,在获取到I帧后能解码出相应的图像,而P帧和B帧需要依赖相邻的帧才能解码出图像;
GOP:( Group of Pictures ) 是一组连续的画面,由一张 I 帧和数张 B / P 帧组成,是视频图像编码器和解码器存取的基本单位,它的排列顺序将会一直重复到影像结束。
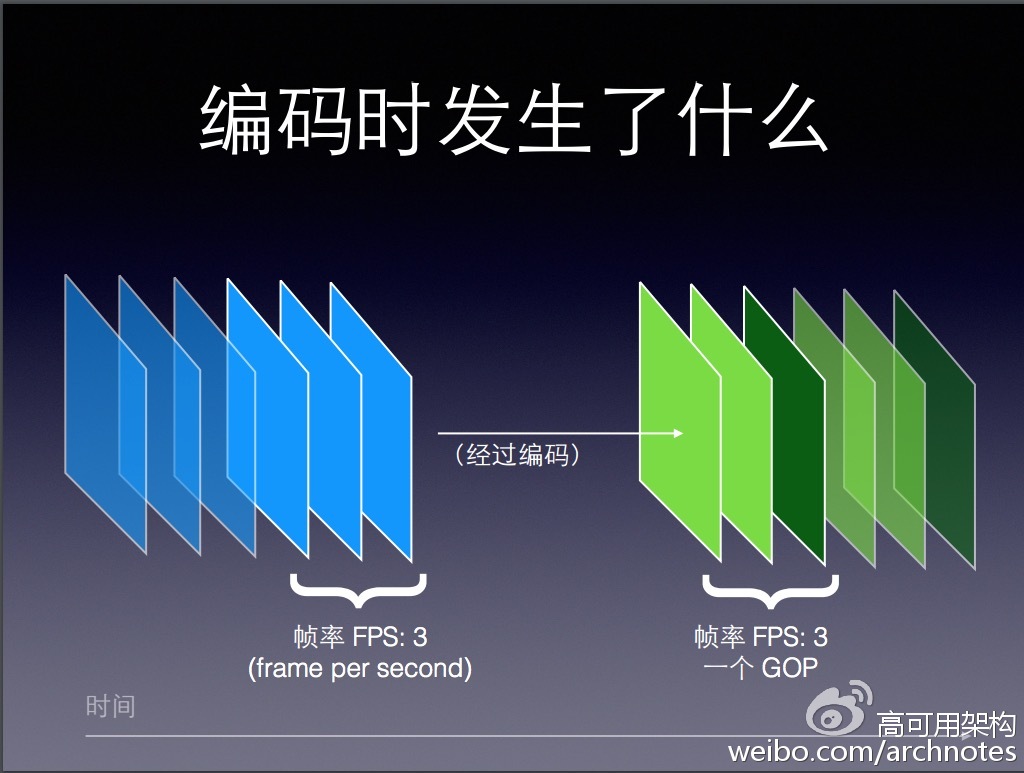
GOP间隔:是指一个画面序列中相邻两个I帧的间隔时间,如图所示:
封装格式:音视频文件封装格式有avi、rmvb、flv、mkv、MP4等等,封装格式就是把音视频数据打包成一个文件的规范。一般会包含音视频编码类型,时间戳,采样率等信息,方便接收方解析出原始数据。
视频码率:码率的单位为kbps,指每秒视频数据量,其值跟每秒视频帧数FPS,图像分辨率以及编码器压缩率有关。
首屏时间:用户点击一个视频到第一个视频画面展示出来的这段时间,是衡量直播体验的关键数据。
我们的优化目标就是加快首屏时间,提高直播体验。所以需要先整理出从用户点击到视频出现这个流程有哪些阶段,然后分析各个阶段是否有可优化的空间来达到减少首屏时间的目标。
顶部流程优化
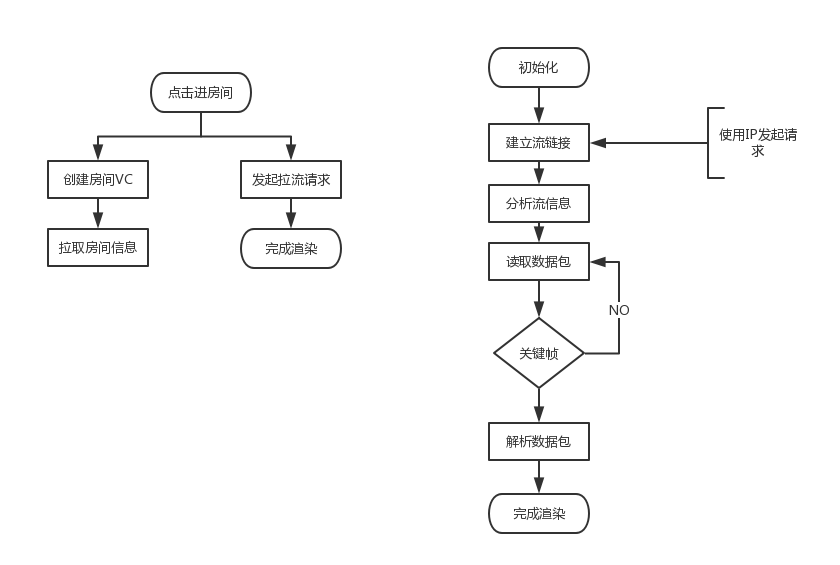
原来的进房间流程如下图所示:
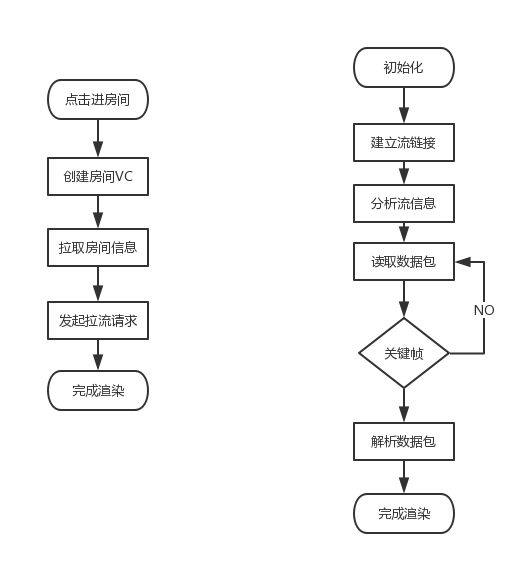
左边的流程图问题很明显,其实拉流和拉房间信息不应该相互依赖,所用的数据应该在用户点击房间前准备好,这个问题的来源是刚接手做第一个版本的时候后台人手不足,移动端只能使用PC端原有的接口来做,这是妥协的结果。
分析
进房间流程
通过插入监控代码计算各个阶段的耗时
创建VC平均耗时:143.428350ms
拉取房间信息平均耗时:458.756419ms
这两个阶段是可以和拉流并行的,完全可以优化掉,在用户点击进房间时同时发起拉流请求和创建房间VC流程以及拉取房间信息。
拉流流程
通过和CDN提供商了解到,他们能提供获取最优CDN IP的接口,该接口可以根据用户所在IP和CDN分布情况返回给用户最优路线,加快连接和视频加载速度,同时减少了通过域名访问的DNS解析时间。
优化
经过分析我们很明显的得到如下的方案:
在列表加载流地址信息,拉流不依赖与房间信息,可以并行请求;
用户点击同时发起拉流动作,不依赖与房间VC的创建,减少房间VC创建耗时;
应用启动预加载对应CDN提供商IP,在发起拉流请求时使用IP拉流,提高连接速度;
结果
经过流程上的优化,在相同网络下多次数据取平均值做数据对比,优化前后平局耗时减少0.6s左右,基本上跟之前分析结果一致。 优化前首屏耗时:2810.096540, 总次数:474,总耗时:1331985.760193 优后后首屏耗时:2207.551701, 总次数:427,总耗时:942624.576327
这个数据离秒开差距还是有点大的,接下来只能从IJKPlayer拉流流程中分析出耗时的原因。
底层环节优化
分析
通过分析IJKPlayer拉流流程如下:
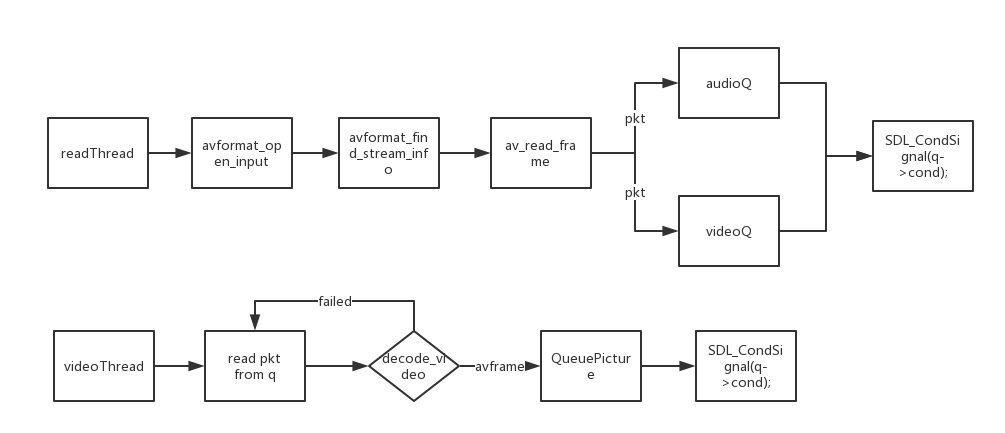
通过打时间戳点发现,有两个阶段耗时比较多:
avformat_find_stream_info: 主要是读一些包(packets ),然后从中提取流的信息。包括获取流解码器,打开对应编码器,从流信息中得到设置编码器的参数等。具体功能可以看这里
decode_video: 这个方法会判断当前帧能否解码,要解码的第一帧必须是关键帧,后续的非关键需要依赖第一个关键帧才能解析出来,在测试中发现此方法得到第一个关键帧之前会丢弃最多两百多个数据包,还有从手机直播的视频流丢弃的数据包相比PC直播的少。
对于第一个问题,如果提前知道拉取的视频流信息,和解码器,那么是可以跳过这个方法,不过需要所有的参数都设置对,对于推流端不确定的情况很难去跳过这个方法,因为参数设置错误,解码器就解不出视频帧,网上有人给出了优化方案,但是我并没有成功过。还有一种方式是通过设置参数限制这个方法的分析时间。可以通过IJKPlayer的参数设置,局限性是如果设置的时间过小可能分析不出足够的流信息导致解码失败。所以没有从这个点优化;
1
| |
针对decode_video获取第一个关键帧之前会丢弃很多数据包的问题分析
实验表明,不同来源的流丢弃的数据包数量不同,PC端的流最大丢弃200多个数据包,而手机端推流一般最多在40几个数据包,这导致播放PC端的流平局耗时比播放手机端的流大;
通过使用映客的流地址拉流发现,映客流获取到第一个关键帧之前丢弃的帧数最多在20个左右,使用映客的流播放基本能达到1s-1.5s的首屏时间;
根据这两个实验结果,我们发现,丢弃的帧的数量其实跟推流端一个GOP间隔大小有关系,如果GOP间隔是2秒,FPS是20,那么如果第一帧刚好读取到关键帧之后的非关键帧,那么两秒后才会有第二个关键帧,也就是需要再等20*2 = 40 个包后才能解析出第一个图像;而PC推流端的GOP是主播自定义的或者使用推流工具默认的值,手机端推流的GOP是3s,映客的GOP应该是2s-1s;
得出的结论是可以通过减小GOP间隔来提高加载速度;
但是GOP并不一定设置的越小越好,GOP越小将导致压缩率越低,同样时间长度的视频体积越大,也可能导致加载速度慢。直播应用GOP间隔一般设置为2s或者1s; 即使设置为1s,从读取到第一帧到解析出第一个图像的耗时期望值为0.5s,加上其他的连接建立等其他的环节,网络速度的影响,也很难达保证稳定的秒开目标。网络正常的情况下平均耗时在1.5s左右。而且我们的PC端推流GOP参数无法控制,不同的主播用的推流工具还不一样,她们也不会去设置这个参数。这个优化只能控制从手机推流的视频流的加载时间。
进一步分析
由于和CDN提供商沟通不畅,我们一直觉得他们没有做关键帧缓存,所以下发的第一个视频帧不是关键帧,导致会读取到很多非关键帧,增加首帧渲染耗时。后来通过进一步了解,他们说他们确实是做了关键帧缓存,并且下发的第一个视频帧一定是关键帧。然而我并不相信,因为从终端打出来的log数据,第一个开始解码的帧并不是关键帧。当然我也开始怀疑是不是在解码第一个帧之前丢弃了一些数据,将关键帧丢弃了。
验证是否丢弃了关键帧
使用应用播放一个本地完整的flv文件,发现仍然会丢弃一部分非关键帧。这就有问题了,一个完整的视频文件第一帧应该是关键帧的,然而它不见了。
使用flv分析工具确认,文件第一帧确实是关键帧。
从以上的验证得到的结论是,IJKPlayer拉流在解码数据包之前的步骤把关键帧丢弃了。
跟踪代码
通过阅读IJKPlayer的代码,发现IJKPlayer并没有丢弃数据包的逻辑,于是只能深入到ffmpeg的源码中找原因
拉流流程主要调用了这几个方法,逐个分析:
1 2 3 4 5 6 | |
最终发现,在avformat_find_stream_info有一个逻辑
1 2 3 4 5 6 | |
如果设置了AVFMT_FLAG_NOBUFFER 参数为YES,那么用来分析流信息的数据包将不会存到buffer中。
WTF我此刻的心情,无以言表,尼玛,我们的代码确实设置了这个参数,而且还写着注释
1
| |
把这个一句注释之后发现,世界更美好了。
优化
经过分析得到的优化方案:
推流端GOP间隔时间设置为2s;
拉流端不设置nobuffer参数;
就两个参数的变化。av_read_frame读取到的第一个数据包就是关键帧。不需要丢弃任何非关键帧数据。达到秒开的目标。
结果
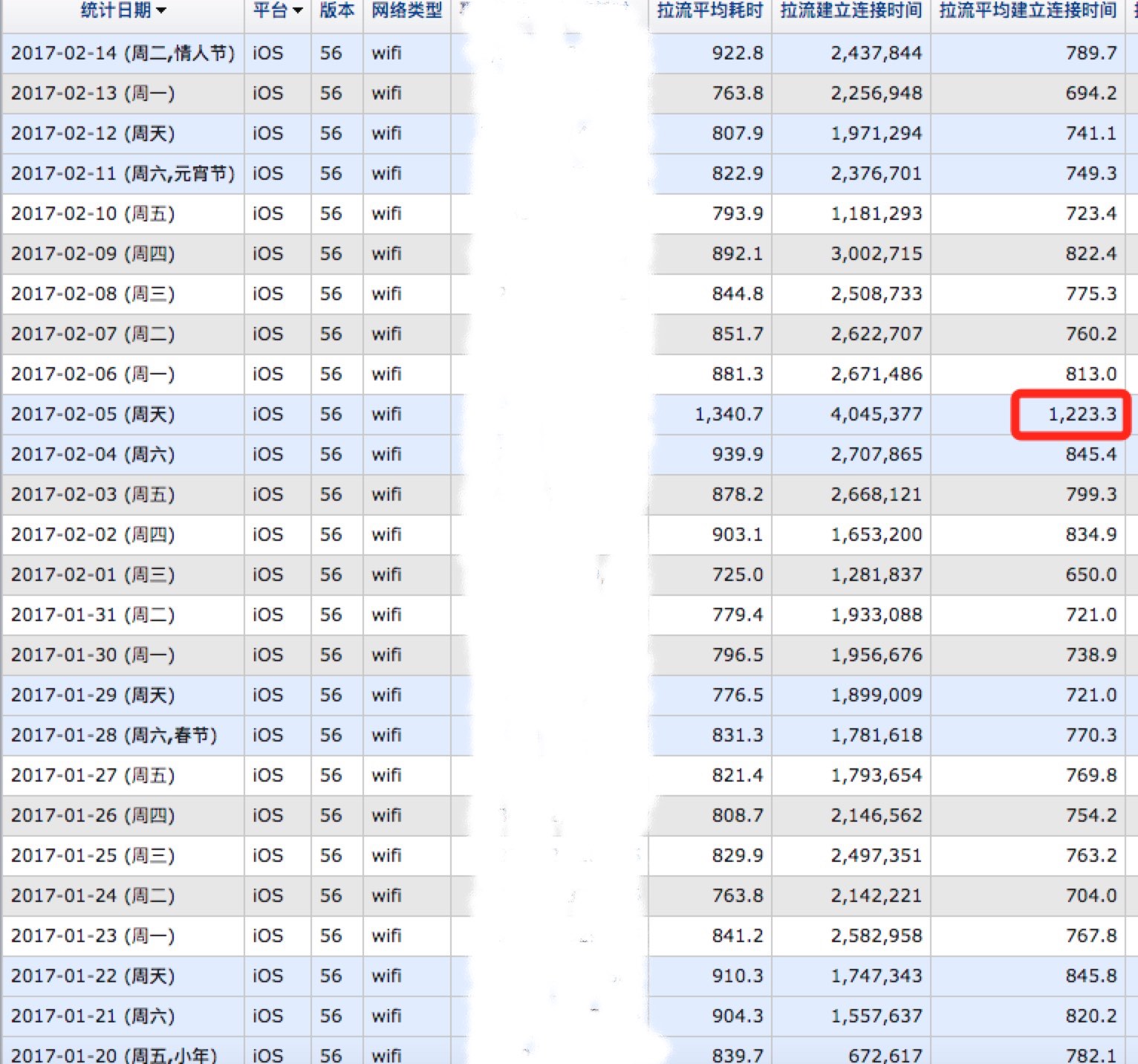
下面是现网数据上报统计的结果,基本在一秒内看到首屏画面,实际的体验比之前好了很多。
推流端优化点
自适应码率
自适应码率是只通过网络传输速率的反馈,推流端动态调整编码平局码率,提高带宽利用率。当网络状态比较差时可以传输质量较低的视频,而当网络状态变好时可以传输较清晰的视频。避免由于网络阻塞导致断流卡顿。现在很多推流端都已近做了这种优化,包括VideoCore和LFLivekit。
编码等级选择
H.264有四种画质级别,分别是BP、EP、MP、HP:
BP-Baseline Profile:基本画质。支持I/P 帧,只支持无交错(Progressive)和CAVLC;
EP-Extended profile:进阶画质。支持I/P/B/SP/SI 帧,只支持无交错(Progressive)和CAVLC;
MP-Main profile:主流画质。提供I/P/B 帧,支持无交错(Progressive)和交错(Interlaced),也支持CAVLC 和CABAC 的支持;
HP-High profile:高级画质。在main Profile 的基础上增加了8x8内部预测、自定义量化、无损视频编码和更多的YUV 格式;
上面解释了各种画质等级支持的特性。具体到推流的选择上,我们考虑的有几点:
观众端是否支持该种编码等级的解码;
越高的编码等级编解码越复杂,压缩率越高,同样的网络速率能传输更多的视频信息;
观众端解码效率是否能流程的解码不出现卡顿。
首先现在的设备基本上都支持者四个等级的解码。我们要考虑的是在播放段的解码效率选择最高的编码等级。我们没有去验证过各种低端设备对各个编码等级解码效率,但是我们现在用的是main profile 没有发现由于解码效率而出现卡顿的现象。(PS. 映客使用的是Baseline Profile)。
总结
优化是一个渐进的过程,从表面显而易见的开始,逐步拆解流程,找到可能的优化点,对这些点逐个分析,找到性能瓶颈,然后想办法解决。当然优化有时也需要权衡代价和效果,重点先解决性价比比较高的优化点。